삼성전자 연구진이 MRAM(자기저항메모리, Magnetoresistive Random Access Memory)을 기반으로 한 인-메모리(In-Memory) 컴퓨팅을 구현하고, 연구 결과를 영국 현지시간 12일 세계적인 학술지 ‘네이처(www.natu...
![]() 2022.01.13
2022.01.13
삼성전자 연구진이 MRAM(자기저항메모리, Magnetoresistive Random Access Memory)을 기반으로 한 인-메모리(In-Memory) 컴퓨팅을 구현하고, 연구 결과를 영국 현지시간 12일 세계적인 학술지 ‘네이처(www.natu...
![]() 2022.01.13
2022.01.13

디지털 트랜스포메이션을 진행 중인 기업들은 일반적으로 핵심 비즈니스 시스템과 하이브리드 클라우드 인프라 사이의 민첩하고 효율적인 실시간 통합을 필요로 한다. 핵심 비즈니스 시스템이 메인프레임인 경우, 이런 실시간 통합을 어떻게 달성할 수 있을까? 정답...
인메모리 디지털 통합 허브 메인프레임 실시간 데이터 통합 인메모리 데이터 그리드
![]() 2021.05.10
2021.05.10
디지털 트랜스포메이션을 진행 중인 기업들은 일반적으로 핵심 비즈니스 시스템과 하이브리드 클라우드 인프라 사이의 민첩하고 효율적인 실시간 통합을 필요로 한다. 핵심 비즈니스 시스템이 메인프레임인 경우, 이런 실시간 통합을 어떻게 달성할 수 있을까? 정답...
![]() 2021.05.10
2021.05.10

4월부터 단독 CEO로 재직 중인 크리스티안 클라인이 온라인으로 진행된 자사의 주력 행사에서 지속가능성과 함께 더 많은 업종별 솔루션을 공급하려는 방침을 강조했다. SAP의 연례 컨퍼런스인 사파이어 나우(Sapphire Now)에서 SAP...
![]() 2020.06.30
2020.06.30
오라클이 자사의 금융 애플리케이션에서 인메모리 그래프 시각화 툴인 인베스티게이션 허브(Investigation Hub)의 활용이 가능해졌다고 밝혔다. 오라클 파이낸셜 서비스에서 제공하는 인베스티게이션 허브는 오라클 엔터프라이즈 케이스 매니...
![]() 2020.06.10
2020.06.10

인메모리 빅데이터 처리 프레임워크인 아파치 스파크(Apache Spark)가 엔비디아 래피즈(RAPIDS)를 기반으로 GPU 가속화를 지원할 예정이다. 아파치 스파크가 곧 공개될 3.0 버전에서 네이티브 GPU 가속화를 지원한다. 무엇보다도 현재 스...
![]() 2020.05.19
2020.05.19

NLP 기술과 인메모리 데이터베이스를 사용해 의사의 메모에서 거의 실시간으로 데이터를 추출하고 분석하는 업체인 머시 테크놀로지 서비스(Mercy Technology Services)가 치료 결과를 개선하고자 데이터 분석해 의사들에게 도움을 주고 있다....
CIO 마스터 데이터 관리 환자 SAP HANA NLP Mercy Technology Services MTS 머시 테크놀로지 서비스 메타데이터 관리 치료 자연어 처리 EMR 빅데이터 데이터베이스 인메모리 의료 분석 병원 MDM 인공지능 진료 차트
![]() 2020.03.17
2020.03.17
NLP 기술과 인메모리 데이터베이스를 사용해 의사의 메모에서 거의 실시간으로 데이터를 추출하고 분석하는 업체인 머시 테크놀로지 서비스(Mercy Technology Services)가 치료 결과를 개선하고자 데이터 분석해 의사들에게 도움을 주고 있다....
![]() 2020.03.17
2020.03.17

ERP(Enterprise Resource Planning)시스템은 기업 전반의 운영 정보를 중앙 데이터베이스를 기반으로 저장, 관리 및 활용하여 기업의 업무 프로세스를 시스템으로 처리할 수 있도록 지원하는 핵심 정보시스템이다. ERP라는 용어가 처음...
![]() 2020.02.03
2020.02.03
SAP 코리아에 따르면 미디어커머스 전문 기업인 브랜드엑스코퍼레이션이 SAP S/4HANA를 도입해 2020년 중 구축 완료할 계획이라고 밝혔다. 온라인에 최적화된 브랜드를 개발하고 인큐베이팅하는 브랜드엑스는 즉각적인 시장 대응을 위한 빠...
![]() 2019.11.04
2019.11.04

전세계 1만 이상의 기업 사용자가 SAP 클라우드 플랫폼을 사용 중으로 알려졌다. SAP의 CTO인 비요른 게르케 SAP의 PaaS는 모바일 구현 클라우드 애플리케이션을 구축하고 확장하기 위한 인메모리 기능, 핵심 플랫폼 서비스, 마이크...
![]() 2018.09.21
2018.09.21

LHC 실험 데이터 분석에서의 데이터 가시화 – 이벤트 및 모니터링 데이터 LHC 실험에서 사용되는 데이터 가시화 방법을 같이 살펴보면서 빅데이터를 활용할 때 데이터 가시화와 큐레이션이 왜 중요한지 같이 생각해보자. 먼저, 데이...
![]() 2018.06.27
2018.06.27
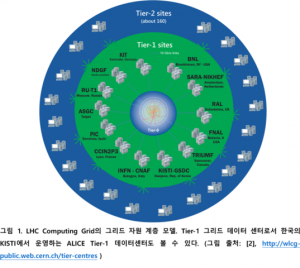
LHC 빅데이터와 LHC Computing Grid의 계층 구조 LHC 빅데이터를 해결하기 위한 분석 인프라로 LHC Computing Grid가 오늘날 클라우드 컴퓨팅의 주요 기술 중 하나인 가상화를 이종 자원에서 작업 실행 환경의 다양성을 극복하...
![]() 2017.11.08
2017.11.08

HPE가 세빗에서 컴퓨팅 아키텍처 근간을 혁신하려는 목적으로 개발한 ‘더 머신’을 일부 공개했다. ‘새 머신’(new machine)이 주말 내내 충돌 없이 가동되는 상황을 앤드류 휠러(Andrew Wh...
![]() 2017.03.27
2017.03.27

데이 앤 짐머맨의 CIO 산카라 비쉬 비스와나단은 IT관리자에게 백오피스 기술 문제에 관해 현업에게 조언할 것으로 요구했다. 현재 그는 내부 운영 역량 자동화를 통해 고객에 응대할 수 있도록 디지털 변혁을 추진하고 있다. CIO들은 종종 ...
![]() 2017.03.16
2017.03.16

SAP가 2016년 클라우드 점유율, 매출, 순이익, 목표치 등 모든 면에서 성공했다고 밝혔다. SAP는 2016년 클라우드 매출이 큰폭으로 증가해 2017년과 2020년에 대한 예측치를 상향 조정했다. 이 회사의 2016년 클라우드...
![]() 2017.01.25
2017.01.25

2017년이 시작됐다. 하지만, 기업들은 이제야 데이터 조작성(Operationalising)을 갖게 됐다는 이야기를 하고 있다. 조작성이란 실제 이용할 수 있는 유용한 데이터를 이 데이터가 필요한 때와 장소에 맞게 현업 사용자에게 전달해야 한다는 의...
![]() 2017.01.03
2017.01.03

스플라이스 머신의 관계형 데이터베이스 2.0 버전이 최근 소개됐는데, 이 제품은 하둡의 확장성과 스파크의 인메모리 성능을 모두 갖췄다는 것이 특징이다. 이미지 출처 : Thinkstock 스플라이스 머신(Splice Machine)이 지...
![]() 2015.11.30
2015.11.30

인튜이트(Intuit)의 빌 로콘졸로 데이터 엔지니어링 부사장은 '데이터 호수(Data Lake)'에 온 몸을 던졌다. 스마터 리마케터(Smarter Remarketer)의 딘 애보트 최고 데이터 과학자는 클라우드를 향해 나아가고 있다....
![]() 2014.10.27
2014.10.27

앞으로 몇 달 안에 IT자격증을 취득할 생각이라면, 클라우드와 보안 관련 자격증을 유망할 것으로 기대됐다. 애자일 개발 관련 교육도 좋을 것 같다. 그러나 푸트파트너(Foote Partners)의 최근 분기 보고서에 따르면, 다른 그 누...
![]() 2014.10.01
2014.10.01