CERN(유럽입자물리연구소)이 연구 업무 증가에 따라 데이터센터와 기술 네트워크의 용량을 확장하기 위해 주니퍼의 네트워킹 솔루션을 도입했다고 주니퍼 네트웍스가 26일 발표했다. CERN은 주니퍼 네트웍스 QFX 시리즈 스위치, EX 시리즈...
![]() 2019.12.26
2019.12.26
CERN(유럽입자물리연구소)이 연구 업무 증가에 따라 데이터센터와 기술 네트워크의 용량을 확장하기 위해 주니퍼의 네트워킹 솔루션을 도입했다고 주니퍼 네트웍스가 26일 발표했다. CERN은 주니퍼 네트웍스 QFX 시리즈 스위치, EX 시리즈...
![]() 2019.12.26
2019.12.26

애자일 프로젝트 관리란? – 스크럼으로 애자일 맛보기 켄트 벡을 비롯한 일부 소프트웨어 엔지니어들이 왜 소프트웨어 엔지니어들은 항상 야근과 과로에 시달려야 하는가, 소프트웨어 프로젝트는 왜 일정을 맞추지 못하고 과도한 요구 사항 변화와 이로 인한 일정...
![]() 2019.10.02
2019.10.02

"인공지능을 광고하는 제품 중 비결이 있다고 할만한 제품은 거의 없다. 사람들은 혁신적인 인공지능이 여전히 매우 기초적인 단계에 있다고 여기고 있으며, 우리는 훨씬 더 발전할 수 있다." - 글래스윙 벤처스(Glasswin...
![]() 2019.04.23
2019.04.23

LHC 실험을 수행하는 물리학자들과 연구자들의 특성 지금까지 LHC 실험을 위한 만든 LHC 가속기와 네 개의 검출기, 그리고 데이터 가공 및 분석을 위한 LHC 데이터 처리 시스템과 WLCG 그리드 컴퓨팅 기술을 소개하면서 빅데이터 기술의 모든 요소...
![]() 2018.12.28
2018.12.28

CERN은 왜 오픈소스 컨퍼런스 관리 소프트웨어를 만들었나? – CERN의 Indico 앞서 자세히 소개한 그리드와 클라우드 컴퓨팅 기술, 그리고 팀 버너스 리의 월드 와이드 웹과 같이 현대 인터넷을 만든 다양한 정보 기술들이 탄생한 CER...
![]() 2018.11.27
2018.11.27

암호화 이메일 서비스 업체인 포로톤메일(ProtonMail)이 iOS 기기에서 사용할 수 있는 단독형 VPN(virtual private network) 앱을 발표했다. 이에 따라 업체가 지원하는 운영체제는 윈도우와 맥OS, 리눅스, 안드로이드, 그리...
![]() 2018.11.21
2018.11.21
암호화 이메일 서비스 업체인 포로톤메일(ProtonMail)이 iOS 기기에서 사용할 수 있는 단독형 VPN(virtual private network) 앱을 발표했다. 이에 따라 업체가 지원하는 운영체제는 윈도우와 맥OS, 리눅스, 안드로이드, 그리...
![]() 2018.11.21
2018.11.21

LHC 실험을 위한 협력 체계의 구조 LHC는 지구에서 가장 큰 기계일 뿐만 아니라, 건설 및 운영 비용에서도 NASA의 스페이스 셔틀 프로젝트, 허블 망원경과 같은 우주 과학 실험과 현재 프랑스 카다라슈에 건설 중인 ITER 핵융합 실험로와 함께...
![]() 2018.10.26
2018.10.26

LHC 실험과 뉴로모픽 엔지니어링 LHC 실험과 같은 거대과학 실험 장치는 건설에만 10~20년이 걸리고, 대량 생산을 위한 물건이나 장치를 만드는 일이 아닌 세계에서 하나뿐인 실험 장치를 만드는 일이다 보니 큰 비용이 들고 그에 따르는 위험 부담...
![]() 2018.09.27
2018.09.27

LCG 데이터 병렬 처리 프레임워크 - PROOF 본 연재의 여섯 번째 글에서 잠시 소개했던 LHC 이벤트 데이터를 분석 과정을 잠시 되새겨 보기로 하자. LHC 이벤트 데이터 분석 과정은 먼저 검출기의 Level-1 트리거와 고수준 트리거(hig...
![]() 2018.03.23
2018.03.23

CMS 온라인 데이터 수집 시스템의 모니터링 문제 흔히 모니터링하면 어떤 시스템의 상태를 관찰하고 운영하기 위해 필수적으로 만들어야 하는 기능이기도 하면서, 왠지 첨단 기술이 들어가지 않는 허드렛일이라는 생각을 많이 하게 되는 것 같다. 하지만, ...
CIO root MOLAP ROLAP PALO 넘파이 파이둡 파이스파크 엑스큐브 BSS 싸이파이 CERN 김진철 빅데이터 하둡 스플렁크 파이썬 데브옵스 R OSS 스파크 큐레이션 마이크로소프트 엑셀
![]() 2018.02.26
2018.02.26
CMS 온라인 데이터 수집 시스템의 모니터링 문제 흔히 모니터링하면 어떤 시스템의 상태를 관찰하고 운영하기 위해 필수적으로 만들어야 하는 기능이기도 하면서, 왠지 첨단 기술이 들어가지 않는 허드렛일이라는 생각을 많이 하게 되는 것 같다. 하지만, ...
![]() 2018.02.26
2018.02.26
.300x240.png)
CMS 검출기에 영혼을 주는 CMS 온라인 소프트웨어 지난 열두번째 글에서 소개한 Level-1 트리거는 CMS를 비롯한 LHC 검출기에서 원시 데이터 처리를 위해 데이터 스트림이 가장 먼저 만나는 시스템이다. 초당 1TB 이상 검출기 센서에서 쏟...
![]() 2018.01.29
2018.01.29

지난 2015년 포레스터는 기업의 하둡 도입이 필수가 되고, 데이터에서 가치를 끌어내고자 하는 모든 기업은 최소한 하둡을 고려해야 한다고 예측한 바 있다. 하둡이란 무엇인가? 오픈소스 아파치 소프트웨어 재단은 하둡을 ‘분산 컴퓨팅 ...
![]() 2017.12.21
2017.12.21
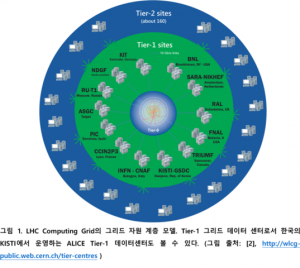
LHC 빅데이터와 LHC Computing Grid의 계층 구조 LHC 빅데이터를 해결하기 위한 분석 인프라로 LHC Computing Grid가 오늘날 클라우드 컴퓨팅의 주요 기술 중 하나인 가상화를 이종 자원에서 작업 실행 환경의 다양성을 극복하...
![]() 2017.11.08
2017.11.08
.300x240.png)
클라우드 컴퓨팅의 서막 – CERN은 왜 클라우드 컴퓨팅이 필요했나? LHC 실험과 인공지능 기술에 대한 내용을 더 다루기 전에, 독자들의 이해를 더 쉽게 돕기 위해 클라우드 컴퓨팅과 LHC 실험과의 관계를 살펴보고 지나가려 한다. 오늘은...
![]() 2017.09.25
2017.09.25

CERN이 인공지능 기술을 소환한 이유 – 2015년 LHC 데이터 과학 워크샵[3] 2015년 11월 9일, CERN의 고에너지 물리학자들과 전세계의 인공지능 기술 전문가들이 모여 CERN의 검출기 데이터 처리 및 분석에 최신 인공지능 ...
![]() 2017.08.28
2017.08.28

LHC 실험 데이터의 복잡성과 인공지능 기술 이번 글부터 앞으로 세, 네 번에 걸쳐서 빅데이터 비즈니스에서 인공지능 기술이 왜 중요하고 어떻게 활용해야 하는지 같이 살펴보려고 한다. 최근 딥러닝이 IT 기술계에서 크게 관심을 끌면서 인공지능 기술에 ...
![]() 2017.07.26
2017.07.26

LHC 실험 데이터 가공 과정과 데이터 형식 이번 글에서는 CMS에서 데이터를 저장하는 방법을 살펴보면서 데이터 형식의 중요성에 대해서 생각해보자. 그리고, 이번 글까지 빅데이터 수집에 관해 썼던 네 편의 글에 걸쳐 살펴본 내용을 바탕으로 비즈니스를...
CIO 빅데이터 메타데이터 양자역학 김진철 유럽입자물리학연구소 CERN LHC 입자검출기
![]() 2017.07.05
2017.07.05
LHC 실험 데이터 가공 과정과 데이터 형식 이번 글에서는 CMS에서 데이터를 저장하는 방법을 살펴보면서 데이터 형식의 중요성에 대해서 생각해보자. 그리고, 이번 글까지 빅데이터 수집에 관해 썼던 네 편의 글에 걸쳐 살펴본 내용을 바탕으로 비즈니스를...
![]() 2017.07.05
2017.07.05

LHC 검출기 및 가속기 데이터의 수집과 측정 지난번 연재(How-to-Big Data 4 – 빅데이터 수집에 관한 생각 (2))에서 데이터 수집의 중요성에 대해서 강조했다. 빅데이터 가공 과정에서 첨단 기술이 가장 많이 필요한 부분은 ...
![]() 2017.05.26
2017.05.26