
데이트브릭스가 아파치 스파크 데이터 프레임에서 허깅페이스(Hugging Face)의 데이터세트를 보다 쉽게 활용할 수 있도록 기술을 개선했다고 26일 밝혔다. 허깅페이스와 협업을 통해 만든 이번 기술로 사용자는 AI 모델 개발 과정에서 필요한 고품질 ...
![]() 2023.04.27
2023.04.27

스트리밍 데이터는 보통 센서, 서버 로그와 같은 수많은 데이터 소스에 의해 지속적으로 생성된다. 스트리밍 데이터 레코드는 대체로 작아서 각각 몇 킬로바이트에 불과하지만 수가 많고 끊임없이 이어진다. 여기서는 스트리밍 데이터에 대한 기본 정보와 함께 스...
![]() 2022.03.02
2022.03.02
스트리밍 데이터는 보통 센서, 서버 로그와 같은 수많은 데이터 소스에 의해 지속적으로 생성된다. 스트리밍 데이터 레코드는 대체로 작아서 각각 몇 킬로바이트에 불과하지만 수가 많고 끊임없이 이어진다. 여기서는 스트리밍 데이터에 대한 기본 정보와 함께 스...
![]() 2022.03.02
2022.03.02

이번 글은 지난 글에 이어 2017년 1월부터 지금까지 필자가 소개했던 빅데이터 활용 교훈의 핵심들을 다시 정리해보려고 한다. 지난 쉰 두 번째 글에서는 빅데이터 비즈니스와 관련된 기술의 종류와 활용법에 대해 살펴본 1회부터 21회까지의 기고 내용을 ...
![]() 2021.05.31
2021.05.31

이번 글과 다음 글에서는 지난 2017년 1월부터 지금까지 필자가 정리했던 빅데이터 활용 교훈의 핵심을 정리해보는 시간을 가지려고 한다. 필자가 기고를 시작했던 2017년부터 지금까지 빅데이터 기술이나 데이터 과학 활용 양상이 많이 발전했어도 많은 기...
![]() 2021.04.27
2021.04.27

이번 글은 필자가 지금까지 데이터 과학자로 경력을 쌓아오면서 경험했거나 듣고 읽었던 빅데이터 활용 사례들을 중심으로 빅데이터를 활용하는 과정에서 많은 조직이 흔히 저지르는 실수와 오해, 시행착오에 대해서 살펴보고, 이를 어떻게 개선할 수 있을지 같이 ...
![]() 2021.03.29
2021.03.29

애드테크(Ad-tech)로부터 탄생한 ‘고성능 자바 플랫폼’은 고부하 웹, 클라우드, 네트워킹, 마이크로서비스 애플리케이션에 적합하도록 개발됐다. 여러 자바 기술을 대체하는 ‘액티브J(ActiveJ)’ 플랫폼이 웹, 클라우드, 마이크로서비...
![]() 2020.12.11
2020.12.11

빅데이터 비즈니스 트렌드의 미래로서 사이버 물리 시스템 기반의 지능형 서비스 비즈니스를 꽤 오랜 지면을 할애해서 지난 1년간 살펴보고 있다. 이번 글은 인공지능 기술과 사이버 물리 시스템 사이의 관계, 미래를 살펴보는 마지막 글로, 지난 6월 13일 ...
빅데이터 사이버 물리 시스템 인공지능 AI 머신러닝 딥러닝 이코노미스트 가트너 알파고 엔비디아 마이크로소프트 구글 페이스북 챗봇 가상 비서 지능형 서비스 GM 하둡 스파크 텐서플로우 파이토치 디지털 전환 디지털 트랜스포메이션 4차 산업혁명 데이터 댐 아마존 해석가능한 인공지능 XAI
![]() 2020.10.30
2020.10.30
빅데이터 비즈니스 트렌드의 미래로서 사이버 물리 시스템 기반의 지능형 서비스 비즈니스를 꽤 오랜 지면을 할애해서 지난 1년간 살펴보고 있다. 이번 글은 인공지능 기술과 사이버 물리 시스템 사이의 관계, 미래를 살펴보는 마지막 글로, 지난 6월 13일 ...
![]() 2020.10.30
2020.10.30

데이터 및 빅데이터 분석은 비즈니스를 성공시키는 동력이다. 기술을 올바르게 구현하는 것도 힘들지만, 빅데이터 이니셔티브를 이끌어갈 적합한 전문성을 가진 인재들로 구성된 적합한 팀을 구성하는 것은 이보다 더 힘들 수도 있다. 빅데이터 이니셔티브를 성공...
![]() 2020.09.08
2020.09.08

일본 전자상거래 대기업 라쿠텐의 미국 내 자회사인 라쿠텐 리워즈가 하드웨어 비용을 줄이고 더 쉽게 자산을 관리하기 위해 하둡 대신 새로운 시스템을 도입했다. 캘리포니아에 있는 라쿠텐 리워즈는 웹에서 제휴 마케팅 링크로 돈을 버는 쇼핑 포인...
![]() 2020.06.25
2020.06.25

아파치 스파크(Apache Spark)는 매우 큰 데이터 집합을 대상으로 빠르게 처리 작업을 수행하는 한편, 단독으로 또는 다른 분산 컴퓨팅 툴과 조율해 여러 컴퓨터로 데이터 처리 작업을 분산할 수 있는 데이터 처리 프레임워크다. 거대한 데이터 스토...
![]() 2020.03.23
2020.03.23
아파치 스파크(Apache Spark)는 매우 큰 데이터 집합을 대상으로 빠르게 처리 작업을 수행하는 한편, 단독으로 또는 다른 분산 컴퓨팅 툴과 조율해 여러 컴퓨터로 데이터 처리 작업을 분산할 수 있는 데이터 처리 프레임워크다. 거대한 데이터 스토...
![]() 2020.03.23
2020.03.23

사이버 물리 시스템과 클라우드 컴퓨팅의 관계 지난 서른여섯 번째 글에서 빅데이터를 포함하여 최근 주요 IT 기술 트렌드로 떠오르고 있는 5G, 클라우드 컴퓨팅, 인공지능, IoT, 엣지 컴퓨팅이 발전해 나가는 공통의 지향점으로서 “사이버 물리 시스템(...
CIO NFV 스파크 네트워크 기능 가상화 김진철 엣지 컴퓨팅 OI Autonomic Computing extended perception Network Function Virtualization Operation Intelligence 사이버 물리 시스템 운영 지능 자율 컴퓨팅 사물인터넷 정부통합전산센터 빅데이터 아마존 IBM 마이크로소프트 AWS 애저 오픈스택 데이터 과학자 하둡 인공지능 5G 아마존 웹 서비스 베어메탈 확장된 인지
![]() 2020.01.28
2020.01.28
사이버 물리 시스템과 클라우드 컴퓨팅의 관계 지난 서른여섯 번째 글에서 빅데이터를 포함하여 최근 주요 IT 기술 트렌드로 떠오르고 있는 5G, 클라우드 컴퓨팅, 인공지능, IoT, 엣지 컴퓨팅이 발전해 나가는 공통의 지향점으로서 “사이버 물리 시스템(...
![]() 2020.01.28
2020.01.28

451 리서치가 데이터 관리 전문가를 대상으로 한 조사에 따르면, 데이터양이 늘어나면서 보안이 가장 큰 골칫거리가 됐다. 기업들은 점점 더 많은 양의 데이터를 수집하고 분석해 서비스와 의사 결정을 개선하고 있다. 그러나 새로...
![]() 2019.02.08
2019.02.08

뉴질랜드 정부가 화웨이 5G 장비의 선정을 차단한 가운데, 화웨이가 해명을 요구하고 있다. 뉴질랜드 정부 통신보안국(GCSB)는 국가 안보를 이유로 통신사 스파크(Spark)의 화웨이 5G 장비 배치를 중단시켰다. 화웨이 뉴질랜드의 앤드류 보우워터 ...
![]() 2018.11.30
2018.11.30
뉴질랜드 정부가 화웨이 5G 장비의 선정을 차단한 가운데, 화웨이가 해명을 요구하고 있다. 뉴질랜드 정부 통신보안국(GCSB)는 국가 안보를 이유로 통신사 스파크(Spark)의 화웨이 5G 장비 배치를 중단시켰다. 화웨이 뉴질랜드의 앤드류 보우워터 ...
![]() 2018.11.30
2018.11.30

기술이 발전하면서 점점 더 많은 조직이 협업 툴에 익숙해졌으며 직원들끼리 안전한 인스턴트 메시징 툴을 사용하게 됐다. 이러한 도구는 사무실 내외부에서 팀이 신속하게 커뮤니케이션할 수 있을 뿐만 아니라 이동 중에도 파일과 정보를 신속하게 공유할 수 있게...
![]() 2018.11.14
2018.11.14

노르웨이의 한 작은 마을이 새 데이터센터에서 발생하는 열을 가정과 사무실 난방에 사용하는 실험을 진행하고 있다. 모든 데이터센터 관리자가 현대적인 데이터센터를 운영하는 데 있어서 발열을 처리하는 것이 가장 중요하고 가장 값비싼 요소라는 것을 알고...
![]() 2018.08.29
2018.08.29

LHC 실험 데이터 분석에서의 데이터 가시화 – 이벤트 및 모니터링 데이터 LHC 실험에서 사용되는 데이터 가시화 방법을 같이 살펴보면서 빅데이터를 활용할 때 데이터 가시화와 큐레이션이 왜 중요한지 같이 생각해보자. 먼저, 데이...
![]() 2018.06.27
2018.06.27

아이폰, 아이패드, 맥용 이메일 앱 서비스인 스파크(Spark)가 다양한 공동작업 기능을 추가한 스파크 2.0 버전을 선보였다. 스파크 2.0은 문서와 첨부 파일을 주고받던 기존의 이메일 기능에서 팀 작업의 효율을 향상할 수 있도록 ‘팀을 ...
![]() 2018.05.23
2018.05.23
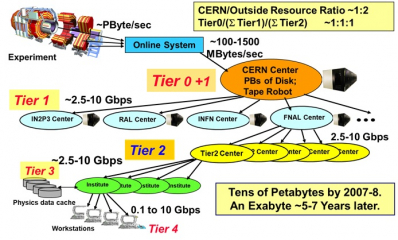
LHC 실험의 데이터 그리드 요구 사항 LHC 컴퓨팅 그리드(LHC Computing Grid)를 구축하면서 해결해야 했던 중요한 문제 중 하나는 LHC 데이터 분석 작업을 기관별로 분담한 분석 대상 이벤트에 맞게 각 기관의 그리드 컴퓨팅 자원으로 ...
![]() 2018.05.23
2018.05.23