
2023년 발생한 주요 서비스 장애 사례를 보면, 마이크로소프트, AWS 같은 쟁쟁한 업체의 아무리 정교한 환경에서도 성능 저하와 네트워크 중단이 나타나고 서비스 중지로 이어질 수 있다. 시스코 산하의 인터넷 및 클라우드 트래픽을 추적...
![]() 2024.02.08
2024.02.08
2023년 발생한 주요 서비스 장애 사례를 보면, 마이크로소프트, AWS 같은 쟁쟁한 업체의 아무리 정교한 환경에서도 성능 저하와 네트워크 중단이 나타나고 서비스 중지로 이어질 수 있다. 시스코 산하의 인터넷 및 클라우드 트래픽을 추적...
![]() 2024.02.08
2024.02.08

지난 11월 17일에 발생하여 3일간 이어졌던 행정전산망 마비 사태는 IT 업계에 큰 이슈가 되었다. 언론에 보도된 바에 따르면 네트워크 구성 장비 중 일부에서의 장애가 원인이라고 하지만 네트워크 전문가들은 해당 원인 만으로 장애가 그렇게 오래 지속되...
![]() 2023.12.01
2023.12.01

이미 경영진까지 교체된 사건이다. 호주 통신사인 옵터스의 서비스 중단은 IT 리더에게 복원력과 재해 복구에 대한 중요한 교훈을 제공한다. 뿐만 아니라 계획을 재평가하고, 대화를 촉발하고, 리스크를 완화하고 후유증을 피하기 위해 투자해야 함을 시사한다....
![]() 2023.11.28
2023.11.28

웹 아웃룩, 익스체인지 온라인, 셰어포인트 온라인, 마이크로소프트 팀즈와 아웃룩 데스크톱 클라이언트에 문제가 발생했다. 마이크로소프트는 장단기적 수정 방안을 강구하고 있다고 밝혔다. 24일 마이크로소프트는 트위터를 통해 일련의 마이크로소프...
![]() 2023.04.26
2023.04.26
웹 아웃룩, 익스체인지 온라인, 셰어포인트 온라인, 마이크로소프트 팀즈와 아웃룩 데스크톱 클라이언트에 문제가 발생했다. 마이크로소프트는 장단기적 수정 방안을 강구하고 있다고 밝혔다. 24일 마이크로소프트는 트위터를 통해 일련의 마이크로소프...
![]() 2023.04.26
2023.04.26

마이크로소프트 네트워크 변경 작업을 실행한 이후, 전 세계 곳곳에서 여러 마이크로소프트 서비스를 이용할 수 없는 문제가 발생했다. 마이크로소프트는 25일 아웃룩과 팀즈를 포함해 여러 마이크로소프트 솔루션에 장애를 일으킨 네트워크 문제를 조사하고 ...
![]() 2023.01.26
2023.01.26

2022년 발생한 주요 중단 사고의 주인공으로는 AWS, 브리티시 항공, 구글, 트위터 등이 있었다. 시스코 소유의 네트워크 인텔리전스 기업 사우전드아이스가 선정한 2022년 중단 사고 톱10 리스트를 살펴본다. 지난 2022년 발생한 각종 중단 사...
![]() 2023.01.17
2023.01.17

ERP에 대한 세간의 나쁜 평판에는 이유가 있다. 복잡하고 값비싼 이 엔터프라이즈 소프트웨어의 역사는 공급사의 횡포, 터무니없는 과장 광고, 어이없는 실패에 대한 이야기로 가득하다. 전사적 자원 관리(ERP)와 고객 관계 관리(CRM) 애...
![]() 2022.11.09
2022.11.09

2022년 7월 8일, 캐나다의 로저스 ISP(Rogers ISP) 네트워크를 어설프게 유지보수 업데이트하는 실수로 인해 캐나다 전역에 최소 12시간 동안 인터넷 액세스 문제가 발생했다. 일부 고객들은 이후 며칠 동안 문제를 겪기도 했다. 약 1,2...
![]() 2022.09.01
2022.09.01

지난 21일 클라우드플레어의 서비스가 중단됐다. 이에 따라 디스코드,쇼피파이, 핏빗, 펠로톤, 각종 암호화폐 서비스 등이 몇 시간 동안 함께 중단됐다. 2010년 설립된 클라우드플레어는 디도스(distributed denial-of-ser...
![]() 2022.06.22
2022.06.22

지메일, 독스, 워크스페이스, 시트, 미트 등 구글 비즈니스 앱과 서비스 서비스 다수가 지난 14일 저녁 30분 이상 중단되는 상황이 발생했다. 구글은 현재 서비스가 대부분은 복원됐다고 밝혔다. 다운 디텍터(Down Detector) 웹 ...
![]() 2020.12.15
2020.12.15

시스코 웹엑스 협업 시스템의 서비스 중단 문제가 1주일이 넘게 지나도록 이어지고 있다. 시스코 웹 사이트에 따르면 9월 25일 대규모 중단 사태가 시작된 이후 관련 웹엑스 서비스에 레이턴시 및 연결 문제 등이 일부 나타나고 있는 중이다. 회사는 ...
![]() 2018.10.05
2018.10.05
시스코 웹엑스 협업 시스템의 서비스 중단 문제가 1주일이 넘게 지나도록 이어지고 있다. 시스코 웹 사이트에 따르면 9월 25일 대규모 중단 사태가 시작된 이후 관련 웹엑스 서비스에 레이턴시 및 연결 문제 등이 일부 나타나고 있는 중이다. 회사는 ...
![]() 2018.10.05
2018.10.05

재해복구계획(DRP)을 수립해 IT인프라와 애플리케이션이 중단되더라도 복구할 수 있도록 해야 한다. 재해가 비즈니스 운영에 필수적인 IT시스템을 공격하면 CIO는 신속하게 확실하게 복구하는 데 중요한 역할을 맡게 된다. 필요한 절차를 문서로 만들...
![]() 2018.01.04
2018.01.04

잘 정립된 클라우드 컴퓨팅 전략으로 새 시스템을 신속하게 적용하고, 혁신적인 디지털 변혁 전략을 가속화 한 좋은 사례는 많다. 그러나 이러한 성과를 누리려고 시도하기 전에 명심해야 할 명확한 진실 한 가지가 있다. 클라우드 전략을 최대한 ...
CIO 컨티뉴어스 딜리버리 데브옵스 확장성 아마존 웹 서비스 중단 온프레미스 컨테이너 AWS 마이그레이션 분석 빅데이터 클라우드 네이티브 애플리케이션
![]() 2017.09.14
2017.09.14
잘 정립된 클라우드 컴퓨팅 전략으로 새 시스템을 신속하게 적용하고, 혁신적인 디지털 변혁 전략을 가속화 한 좋은 사례는 많다. 그러나 이러한 성과를 누리려고 시도하기 전에 명심해야 할 명확한 진실 한 가지가 있다. 클라우드 전략을 최대한 ...
![]() 2017.09.14
2017.09.14

윈도우 10의 다양한 기능과 일부 앱의 경우 기업 사용자의 편의에 맞춰 설정을 변경할 수 있다. 해당 기능이나 앱을 실행해 설정을 변경하는 것도, 완전히 끄는 것도 어느 쪽이든 가능하다. 윈도우 10은 기업 사용자에게 상당히 다양한...
![]() 2016.03.17
2016.03.17
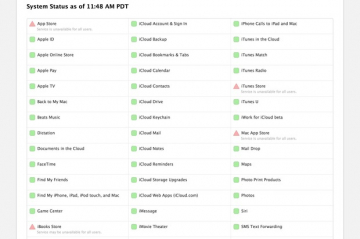
다수의 애플 서비스에 접속하지 못하는 현상이 발생했다는 보고가 이어졌다. iOS 및 맥 앱 스토어, 아이튠즈, 아이클라우드, 회사의 지원 스케줄러 등이 대상이었다. 지난 11일 오전 3시부터 애플 지원 포럼에는 접속 불가를 알리는 포스트가 잇달아...
![]() 2015.03.12
2015.03.12

IT전문가가 고민하는 가장 일반적인 IT문제로 네트워크 속도 저하나 중단이 꼽혔다. 켈튼리서치(Kelton Research)의 조사에 따르면, IT전문가들은 예상치 못한 애플리케이션 변경 요청 때문에 애플리케이션 성능과 가용성이 떨어지며 최악의 경우 ...
![]() 2014.12.04
2014.12.04

모바일 인터넷이 끊기는 사고가 발생하면 평균 140만 명의 사용자가 영향을 받는 것으로 조사됐다. 네트워크가 더 많이 소프트웨어에 의존하게 되면서 소프트웨어 버그가 모바일 인터넷 끊김의 주범으로 등장했다. 지난해 유럽 전역의 고정 및 모바일...
가트너 소프트웨어 조사 네트워크 중단 버그 SDN 소프트웨어 정의 네트워크 무선 인터넷
![]() 2014.09.17
2014.09.17
모바일 인터넷이 끊기는 사고가 발생하면 평균 140만 명의 사용자가 영향을 받는 것으로 조사됐다. 네트워크가 더 많이 소프트웨어에 의존하게 되면서 소프트웨어 버그가 모바일 인터넷 끊김의 주범으로 등장했다. 지난해 유럽 전역의 고정 및 모바일...
![]() 2014.09.17
2014.09.17

올해 IT업체들도 몇 번 공개 사과를 밝혔지만, 큰 관심을 불러일으키지는 못했다. 하지만 네트워크와 컴퓨팅 산업분야에서 안타까움을 자아낸 기업들은 적지 않았다. 함께 살펴보기로 하자. ciokr@idg.co.kr
![]() 2013.09.02
2013.09.02