CERN이 인공지능 기술을 소환한 이유 – 2015년 LHC 데이터 과학 워크샵[3]
2015년 11월 9일, CERN의 고에너지 물리학자들과 전세계의 인공지능 기술 전문가들이 모여 CERN의 검출기 데이터 처리 및 분석에 최신 인공지능 기술을 어떻게 적용할 수 있을지 논의하는 워크샵을 열었다. 11월 9일부터 13일까지 5일간 열린 이 워크샵은 인공지능 기술이 앞으로의 과학 연구를 어떻게 바꿔 갈지 엿보게 하는 중요한 회의였다[2~3].
.png)
이 워크샵에서 지금까지 인공지능 기술을 LHC 빅데이터를 처리, 분석에 적용한 성공 사례들이 소개되었다. 이에 더해서, LHC 빅데이터를 온전하게 활용하지 못하는 현재의 LHC 빅데이터 처리, 분석 기술의 한계를 인공지능을 이용해 어떻게 극복할 수 있을지, 그리고 인공지능 기술을 통해 극복할 수 있을 것으로 보이는 미해결 문제 및 요구사항에 대해서도 소개 되었다. 특히, 인공지능 기술이 LHC 빅데이터 분석에 줄 수 있는 많은 가능성들에 대해서 앞으로의 LHC 업그레이드 계획과 함께 열띤 토론이 이어졌다.
예전의 세번째 글에서 잠시 소개했던 것과 같이, CMS 검출기의 경우 LHC 가속기에서 충돌하는 양성자빔은 초당 4천만 번의 횟수로 원시 이벤트 데이터를 발생시킨다. 이 때문에 초당 약 1TB의 많은 원시 데이터(raw data)가 발생한다[1, 4]. 검출기 1단계 트리거(Level-1 Trigger) 하드웨어 장치에서 원시 데이터 처리에 3.2 마이크로초가 걸리며, 이 3.2 마이크로초 동안 원시 데이터를 보관, 처리할 수 있도록 Level-1 트리거의 전자회로(front-end electronics)가 설계, 제작되었다[1, 4]. 이러한 Level-1 트리거 하드웨어의 동작 특성 때문에 원시 데이터의 샘플링 빈도(sampling frequency)가 100kHZ에 불과하다. 이 얘기는 CMS 검출기에서 수집한 이벤트 원시 데이터의 약 천분의 일만 Level-1 트리거의 필터를 통과하여 고수준 트리거(high-level trigger)로 데이터 처리를 위해 전송될 수 있다는 의미이다[4].
CERN의 물리학자들과 세계 각국에서 모인 인공지능 전문가들이 최신 인공지능 기술의 LHC 빅데이터에의 적용이 가장 효과적일 것으로 본 문제가 바로 Level-1 트리거의 데이터 유실 문제이다. Level-1 트리거는 CMS 검출기의 개발, 건설 당시 가장 빠르게 많은 원시 데이터를 처리할 수 있는 고성능 컴퓨팅 전자회로로 설계, 개발되었다. 당시 전자회로 기술로는 가장 높은 데이터 처리 능력을 보이는 회로였음에도 데이터 처리에 3.2마이크로초가 걸리는 근본적인 한계 때문에 천 번 중 한 번 밖에 이벤트 원시 데이터를 저장할 수밖에 없었던 것이다.
실리콘 스트립 픽셀 센서에서 수집된 천 개의 데이터 중 한 번꼴로 버려지는 이벤트 원시 데이터에는 힉스 입자와 같은 중요한 물리학적 현상에 대한 중요한 정보를 가지고 있는 이벤트 데이터가 있을 수 있다. 어쩌면, LHC가 가동되기 시작한 2008년부터 CMS 검출기가 미처 수집하지 못하고 버린 이벤트 데이터까지 모두 분석을 할 수 있었다면 힉스 입자 이벤트를 2012년보다 훨씬 더 빨리 발견할 수 있었을지도 모른다.
이 이벤트 데이터 유실 문제를 해결하기 위해 물리학자들과 인공지능 기술 전문가들은 딥러닝과 같은 인공지능 기술을 Level-1 트리거 단계에서부터 적용하는 것을 검토하고 있다. Level-1 트리거 단계에서부터 이벤트 데이터가 관찰하고자 하는 현상을 적절하게 담고 있는지 판단할 수 있다면 지금과 같은 이벤트 샘플링 빈도를 유지하면서도 힉스 입자와 같은 중요한 물리학적 현상에 대한 정보를 가진 이벤트 데이터를 조기에 필터링해서 수집함으로써 분석에 유효한 데이터의 양과 품질을 훨씬 더 쉽게 높일 수 있을 것으로 생각한다[3].
최근 영상 분석에 많이 활용되고 있는 합성곱 신경망(convolution neural network; CNN)과 같은 딥러닝 기술을 쓰면 실험에서 목표로 하는 이벤트 데이터일 가능성이 높은 데이터만 지능적으로 수집할 수 있기 때문에 의미 있는 물리학적 현상을 더 효과적으로 발견할 수 있을 것으로 보고 있다. 더군다나 합성곱 신경망과 같은 신경망 아키텍처는 매트릭스 연산 최적화를 통해 FPGA 등의 하드웨어로의 이식과 최적화가 용이하기 때문에 Level-1 트리거와 같은 짧은 지연 시간과 높은 실시간성을 요구하는 분석 단계에도 적합하다.
LHC 이벤트 데이터 분석에 인공지능 기술이 효과적으로 활용될 수 있는 또 다른 문제는, 새로운 입자 발견에 딥러닝 및 기계 학습 기술을 사용하는 것이다. 새로운 입자를 탐색하는 경우 딥러닝 및 기계 학습 기술은 두 가지 측면에서 활용된다. 첫 번째는 딥러닝이나 기계 학습 모델이 일종의 비정형 데이터의 탐색기, 또는 Google과 같은 검색 엔진 같이 활용되는 것이다. 두 번째는 물리학자들이 검출기 영상 데이터와 시뮬레이션 데이터를 육안으로 일일이 대조하면서 찾아내는 과정을 딥러닝이나 기계 학습 모델을 이용해 기계가 대신하여 자동화하여, 매우 많은 양의 데이터를 분석할 때 부딪히는 인간 육체의 한계 때문에 물리학자들이 놓친 이벤트 데이터를 이용해 새로운 입자를 찾아낼 수 있다.
첫 번째로 일종의 비정형 데이터 탐색기같이 활용되는 딥러닝이나 기계 학습 모델이 새로운 입자를 탐색하는 원리는 이렇게 설명할 수 있다. 딥러닝을 비롯한 기계 학습 모델이 가진 고유한 특성인 일반화(generalization) 능력 때문에, 학습할 때 사용했던 데이터와 다른 데이터에 대해서도 꽤 높은 정확도로 판단이나 분류가 가능하다. 기계 학습 모델의 이런 일반화 능력이 실세계(real world) 문제를 기계 학습 기술이 푸는데 기존의 결정론적인 알고리즘 방법에 대해 더 나은 장점이다. 학습된 기계 학습 모델이 학습과정에서 얻은 일반화 능력을 이용해 검출기 이벤트 데이트 중 새로운 입자일 가능성이 높은 이벤트를 좀더 포괄적으로 찾아내어 분석하게 되면 기존의 결정론적인 알고리즘을 이용해 이벤트 데이터를 분석하는 경우보다 더 융통성 있고 유연하게 데이터를 탐색, 분석할 수 있다.
두 번째는
지난번 일곱 번째 글에서 소개한 것과 같이 딥러닝과 기계 학습 기술을 인간의 인지 능력을 자동화하는 용도로 사용하는 것이다. 물리학자들이 육안으로 이벤트 영상을 시뮬레이션 이벤트 영상과 대조하고 판독하는 과정을 딥러닝과 기계 학습 기술이 대신하여 자동화하게 된다. 물리학자들의 두뇌와 육체는 장시간의 데이터 분석에 쉽게 지쳐 데이터를 분석하는 양과 수준에 한계가 있지만, 컴퓨터는 이러한 반복적인 대조 분석과 분류 작업을 지치지 않고 지속해서 할 수 있기 때문에 많은 데이터를 정밀하게 분석할 수 있다. 사람이 실수로 지나칠 수 있는 데이터도 정밀하게 대조, 확인할 수 있기 때문에 사람이 미처 발견하지 못한 새로운 입자를 발견할 수 있는 확률을 높이게 되는 것이다.
마지막으로 딥러닝과 기계 학습 기술이 LHC 검출기 데이터 분석에 유용하게 활용될 수 있는 경우는 검출기 운영 환경의 변화나 검출기 자체의 오류에서 온 오차를 자동으로 다시 캘리브레이션하고 보정해서 실험 데이터의 신뢰성을 높이는 데에 쓰는 것이다. 실제로 LHC 가속기의 네 개의 검출기 중 LHCb 검출기는 특히 온도와 압력의 영향을 많이 받는다. 이러한 온도와 압력 변화에 따른 검출기 특성의 변화 때문에 같은 실험 동안 검출된 이벤트 데이터의 품질을 유지하면서 중요한 이벤트 데이터를 일관성 있게 자동으로 선별하는 것이 어렵다. 최근 LHCb 검출기 연구자들은 터보 스트림(TurboStream, [9])이라고 불리는 방법으로 이벤트 데이터의 크기를 선별적으로 줄이고, 단위 시간에 재구성하는 이벤트의 숫자를 늘려 추가로 얻은 이벤트 데이터를 이용해 온도와 압력의 변화에 따른 LHCb 검출기 파라미터의 보정에 활용하여 수집된 데이터의 품질과 분석 결과를 더 개선할 수 있었다. 그 결과 J/Ψ 중간자(meson)의 특성을 정밀하게 규명할 수 있었다[3, 6-7].
빅데이터 비즈니스 시스템과 인공지능 기술의 콜라보 – 자동화를 통한 인간 정보 처리 능력의 증강
빅데이터와 인공지능의 관련성을 다룬
지난번 일곱 번째 글에서 빅데이터 비즈니스에서의 인공지능 기술의 유용성은 인간의 인지 기능이 필요한 데이터 처리 및 분석과정을 자동화함으로써 얻을 수 있는 비즈니스 운영과 실행의 스피드라고 말한 바 있다[8]. 그렇다면, 무조건 자동화만 하면 좋은 것일까? 이러한 자동화가 어떤 방향으로 이루어져야 더 효과적일까?
인공지능 기술의 한 종류인 패턴 인식 기술을 실험 초기부터 적용하여 빅데이터를 처리해온 LHC 실험 연구자들도, 최근 급격하게 발달한 컴퓨터 기술로 더 활용이 쉬워진 인공지능 기술을 LHC 빅데이터에 좀더 폭넓게 적용하여 입자 물리학 현상 연구를 더 효과적으로 하기 위해 노력하고 있는 것을 앞에서 살펴보았다. 이들 물리학자들이 인공지능 기술을 LHC 빅데이터에 적용하려고 고민하는 문제들을 빅데이터 비즈니스의 관점에서 다시 잘 살펴보자.
힉스 입자와 같은 새로운 입자를 찾아내는데 필요한 단서와 정보를 얻기 위해 데이터를 가공하는 과정마다 사람만이 가진 특별한 인지 능력이나 분석 능력이 필요한 단계가 있다. 사람의 두뇌는 주의집중을 유지하면서 두뇌의 자원을 연속해서 사용하여 특정한 작업을 수행하는 데 한계를 가지고 있어 어느 시간 이상 집중하게 되면 쉽게 지치고 작업의 효율과 정확도도 떨어지게 된다. 이벤트 데이터 분석과 같이 정밀한 지적인 작업이 필요한 일의 경우에는 더 쉽게 지치게 되기 때문에, LHC 검출기에서 생산되는 막대한 데이터를 모두 분석하기에는 역부족이다.
물리학자들이 LHC 빅데이터를 인공지능 기술로 구현한 데이터 분석 자동화 소프트웨어에 넣으면 소프트웨어가 자동으로 힉스와 같은 새로운 입자를 찾아 알려주리라고 생각하고 소프트웨어를 만든 것이 아니다. 위와 같이 사람의 두뇌가 가진 주의집중력과 두뇌 연산 자원의 한계 때문에 오랜 시간 일할 수 없는 약점과 많은 데이터를 빠르게 처리할 수 없는 연산 능력의 한계를 보완할 수 있도록, 인간의 인지 능력과 같은 기능을 수행할 수 있는 소프트웨어를 만들고 이를 고성능 컴퓨팅 시스템을 이용해 분산, 병렬 처리함으로써 대량의 데이터를 쉬지 않고 분석할 수 있도록 데이터 처리, 분석 시스템을 만들어 인간의 연산 능력과 집중력의 한계를 보완한 것이다.
인간의 인지 능력과 같은 기능을 수행하는 데 필요한 소프트웨어 모듈을 만드는데 기계 학습과 인공지능을 쓴 것이고, 이러한 지능적인 소프트웨어의 연산 능력을 크게 향상, 증강하기 위해 수천 대, 수만 대의 컴퓨터를 연결한 고성능 컴퓨팅 시스템을 사용하는 것이다. 사람을 대신해서 검출기 데이터를 분석하고 자동으로 새로운 입자를 찾아주는, 즉 요즘 인공지능에 대한 글에서 많이들 염려하는 인간의 고급 지적 능력을 대체하는 기술을 만들기 위해 인공지능과 기계 학습 기술을 사용한다기보다는 여전히 인간의 고급 지적 능력으로 데이터 분석은 마무리하지만 데이터 분석에 필요한 데이터 처리 및 가공 과정에서 인간의 인지 능력과 지적인 분석 능력이 필요한 부분을 자동화하여 분석 시간과 노력을 줄인 것이다.
또 하나 빅데이터 비즈니스 시스템에서 인공지능 기술의 중요한 쓰임새에 대해 생각해볼 것이 있다. 위의 LHCb 사례에서 살펴본 것처럼, 검출기가 주변 환경에 맞게 적응하여 최적의 이벤트 데이터를 만들어낼 수 있도록 검출기 운영 파라미터를 자동으로 보정, 업데이트할 수 있도록 하는데 기계 학습 기술이 쓰인 것이다. 인체가 끊임없이 변하는 환경에서 생명을 유지하면서 살아갈 수 있는 중요한 특성중의 하나가, 주변 환경의 상태를 끊임없이 인지하고, 이에 맞게 생활 방법을 적응, 변화시키기 때문이다.
이 세상의 모든 것을 데이터화해서 수집하고 처리해서 다시 세상이 조화롭게 유지되도록 피드백을 주는 엄청난 컴퓨터 시스템이 있다면 그러한 컴퓨터 시스템을 우리는 어쩌면 신이라고 부를 수 있을지 모르겠다. 하지만, 우리가 만들 수 있는 빅데이터 IT 시스템은 불행하게도 이 복잡한 세상의 아주 제한된 일부분만을 극히 제한적인 형태의 데이터로 담아낼 수 있을 뿐이다. 이 제한적인 정보를 모으고 처리할 수 있는 시스템이 자신보다 훨씬 복잡하고 많은 변수들을 통해 움직이는 주변 환경의 영향을 받아 오작동하지 않고 데이터의 질을 유지하면서 온전하게 작동하기 위해 사람이 자신의 몸을 환경에 적응하면서 생명을 유지하는 적응 능력을 모방하여 응용할 수 있다.
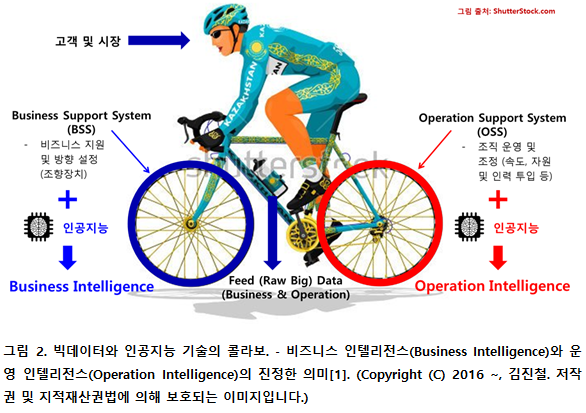
비즈니스의 방향을 정하고, 비즈니스를 수행하고 나아가는 과정에서의 위험 요소들을 미리 판별하고 대응하기 위한 빅데이터 처리를 위해 부족한 인간의 능력을 보완하고 증강하는 측면에서 쓰이는 인공지능 기술은 앞서 네 번째 글에서 소개한 자전거 모델에서 앞바퀴에 해당하는 비즈니스 지원 시스템(Business Support System; BSS)에 부여된 지능으로 볼 수 있다. BSS에 부여한 지능이 바로 진정한 의미에서의 비즈니스 인텔리전스(Business Intelligence; BI), 즉 비즈니스 기계 지능이라 할 수 있다.
비즈니스가 튼튼하고 강건하게 유지되기 위해 비즈니스를 떠받치는 조직과 체계(system)를 유지, 운영하는 시스템이 복잡한 비즈니스 환경의 영향으로 인해 좌초되고 깨어지지 않도록 비즈니스 환경에 맞게 끊임없이 변화하고 적응할 수 있도록 돕는 것이 바로 운영 지원 시스템(Operation Support System; OSS)에 부여된 지능, 즉 오퍼레이션 인텔리전스(Operation Intelligence; OI), 운영 기계 지능이라고 볼 수 있다.
빅데이터 비즈니스 시스템에서의 인공지능은 결코 비즈니스를 수행하는 사람을 대신하거나 대체하기 위해 쓰이는 기술이 아니다. 조직을 구성하고 비즈니스를 수행하는 사람들의 역량을 보완, 증강하여 비즈니스의 스피드와 성과를 크게 향상하는 기술이 되어야 하고, 실제로도 그런 기술이 될 것이다. 그런 의미에서 최근 인공지능과 관련된 담론에서 자주 등장하는 디스토피아적이고 비관적인, 직업과 일에서 인간을 대체하고 지배하는 인공지능은 당분간 나타나지 않을 것이라고 필자는 생각한다.
구글의 인공지능 부문 부사장인 레이 커즈와일이 예언한 특이점(singularity)이 정말로 2040년경에 올 수도 있을 것이다. 현재 매우 빠른 속도로 발전하는 고성능 컴퓨팅 기술, 양자 컴퓨팅 기술을 비롯한 컴퓨팅 소자 기술, 그리고 딥러닝을 포함한 인공지능 기술을 보면 그러한 불안감이 들 수도 있다. 필자는 CERN의 물리학자들이 인공지능 기술들을 활용하는 모습들을 보면서 인공지능 기술이 우리의 비즈니스와 사회를 더 풍요롭고 편리하게 만들어주는 밝은 미래를 본다. 기술 자체는 가치중립적인 것일 수 있어도, 결국 기술을 활용하여 우리에게 필요하고 쓸모 있는 것을 만들고 우리의 인간미를 더 긍정적으로 발전시키도록 기술을 활용하는 것은 우리 자신의 몫이다. 빅데이터와 인공지능 기술을 우리 비즈니스와 생활, 사회를 더 풍요롭게 할 수 있는 증강 기술로써 활용하는 것이 특이점보다 더 빨리 다가올 우리의 미래이고, 현재를 살아가는 우리들에게 주어진 축복이고 선물이다.
[참고문헌]
[1] 김진철, “LHC에서 배우는 빅데이터와 machine learning 활용 방안”, 2016년 9월 28일, A CIO Conversation for Technology Leadership – Breakfast Roundtable 발표 자료
[2] Data Science @ LHC 2015 Workshop, November 9 ~ 13, 2015. (
https://goo.gl/kk5Mnq)
[3] Davide Castelvecchi, “Artificial intelligence called in to tackle LHC data deluge,” Nature Vol. 528, Iss. 7580, pp. 18 ~ 19, 2015.
[4] Wesley H. Smith, “Triggering CMS,” a seminar material at Texas A&M university, April 20, 2011,
[5] J.A. Coarasa for the CMS TriDAS group, “The CMS openstack, opportunistic, overlay, online-cluster Cloud (CMSooooCloud)," a presentation at CHEP2013, 14-18 October 2013 (Amsterdam, The Netherlands.)
[6] P. Baldi, P. Sadowski, and D. Whiteson, “Searching for Exotic Particles in High-Energy Physics with Deep Learning,” arXiv:1402.4735v2, 2014(
https://arxiv.org/abs/1402.4735).
[7] Caterina Doglioni, Dustin James Anderson, Vladimir Gligorov on behalf of the ATLAS, CMS and LHCb collaborations, “Real-time data analysis in ATLAS, CMS and LHCb,” a presentation at Data Science @ LHC 2015 Workshop, November 9 ~ 13, 2015. (https://goo.gl/GCPpuc)
[8] 김진철, “김진철의 How-to-Big Data | 빅데이터와 인공지능 (1)”, CIO Korea 칼럼, 2017년도 7월 26일자. (
http://www.ciokorea.com/news/35006)
[9] Sean Benson, Vladimir Gligorov, Mika Anton Vesterinen, John Michael Williams, “The LHCb Turbo Stream,” Proceedings of the 21st International Conference on Computing in High Energy and Nuclear Physics (CHEP2015), J. Phys.: Conference Series 664, 082004, IOP Publishing, 2015.
[10] CERN Document Archive,
http://cds.cern.ch/ .
 *김진철 박사는 1997년 한국과학기술원에서 물리학 학사, 1999년 포항공과대학교에서 인공신경망에 대한 연구로 석사 학위를, 2005년 레이저-플라즈마 가속기에 대한 연구로 박사 학위를 받았다. 2005년부터 유럽입자물리학연구소(CERN)의 LHC 데이터 그리드 구축, 개발에 참여, LHC 빅데이터 인프라를 위한 미들웨어 및 데이터 분석 기술을 연구하였다. 이후 한국과학기술정보연구원(KISTI), 포항공과대학교, 삼성SDS를 거쳐 2013년부터 SK텔레콤에서 클라우드 컴퓨팅과 인공지능 기술을 연구하고 있다. 빅데이터와 인공지능 기술의 기업 활용 방안에 대해 최근 다수의 초청 강연 및 컨설팅을 수행하였다.
*김진철 박사는 1997년 한국과학기술원에서 물리학 학사, 1999년 포항공과대학교에서 인공신경망에 대한 연구로 석사 학위를, 2005년 레이저-플라즈마 가속기에 대한 연구로 박사 학위를 받았다. 2005년부터 유럽입자물리학연구소(CERN)의 LHC 데이터 그리드 구축, 개발에 참여, LHC 빅데이터 인프라를 위한 미들웨어 및 데이터 분석 기술을 연구하였다. 이후 한국과학기술정보연구원(KISTI), 포항공과대학교, 삼성SDS를 거쳐 2013년부터 SK텔레콤에서 클라우드 컴퓨팅과 인공지능 기술을 연구하고 있다. 빅데이터와 인공지능 기술의 기업 활용 방안에 대해 최근 다수의 초청 강연 및 컨설팅을 수행하였다. ciokr@idg.co.kr