지난 칼럼 ‘김진철의 How-to-Big Data | 연재를 시작하며’에 이어 이번에는 빅데이터 활용에 관한 근본적인 질문에 대해 이야기하려 한다.
유럽입자물리학연구소가 LHC를 건설한 이유
유럽입자물리학연구소(CERN)가 75억 유로, 우리나라 돈으로 약 11조 원(2010년 기준)에 해당하는 막대한 예산을 들여 대형강입자가속기(The Large Hadron Collider; 이하 LHC)를 지은 이유가 무엇일까? 왜 LHC가 필요한 것일까? LHC가 만들어내는 빅데이터가 왜 그렇게 중요한 것일까? LHC의 빅데이터 얘기를 하기 전에 LHC 실험의 배경에 대해서 간략하게 소개하고자 한다. LHC 실험이 시작된 배경과 LHC가 어떤 시설인지를 이해하면 앞으로 하게 될 LHC 빅데이터 시스템에 대한 설명도 다소 쉽게 이해할 수 있을 것이다.
LHC는 일종의 거대한 현미경이다. LHC 가속기는 두 개의 양성자빔을 반대 방향으로 빛의 속도의 99.99999999%까지 매우 빠르게 가속시켜 질량 중심 에너지가 14TeV인 고에너지 상태의 양성자빔 충돌을 일으켜 양성자빔내의 양성자들이 서로 충돌할 때 나타나는 현상을 분석하는 장치다.
그림 1. LHC 가속기의 개요
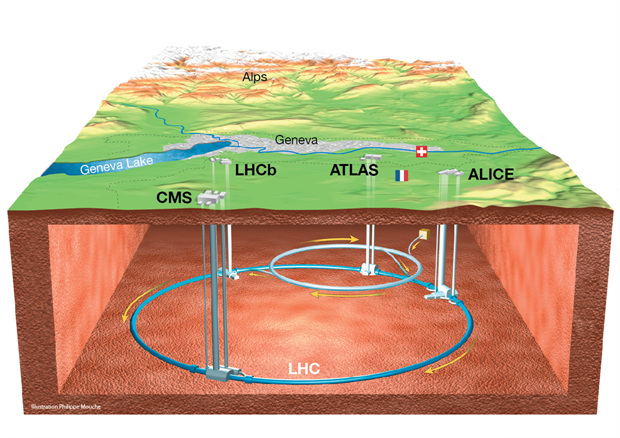 LHC 가속기는 제네바 부근 스위스-프랑스 국경지방 지하 100m에 건설된 둘레 27km의 거대 실험 장치이다[1].
LHC 가속기는 제네바 부근 스위스-프랑스 국경지방 지하 100m에 건설된 둘레 27km의 거대 실험 장치이다[1].
양성자빔들을 서로 충돌시키는 이유는 두 대의 자동차가 서로 부딪칠 때 일어나는 일로 비유할 수 있다. 자동차 두 대가 빠른 속도로 충돌하면, 자동차가 크게 부서지면서 자동차에 있던 각종 부속이나 부품, 구성품들이 차 바깥으로 튀어나오게 된다. 양성자빔이 충돌할 때에도 같은 일이 일어난다.
입자물리학자들이 밝혀낸 바에 따르면 양성자도 우주의 근본 입자, 즉 더 이상 쪼개지지 않는 최소 단위가 아니며, 양성자는 두 개의 업쿼크와 한 개의 다운쿼크로 이뤄진 것으로 밝혀졌다. 양성자빔들이 고에너지로 서로 충돌하면서 양성자 내부에 속박되어 있던 업쿼크와 다운쿼크가 튀어나오게 될 뿐만 아니라, 높은 에너지의 양성자와 쿼크 입자간의 상호 작용에 의해 다양한 새로운 입자가 생성되고 다양한 입자의 상호작용 현상이 나타나게 된다. 이런 현상들을 입자물리학자들은 ‘이벤트’라고 부른다.
그림 2. LHC 가속기의 구조 및 주요 장치들
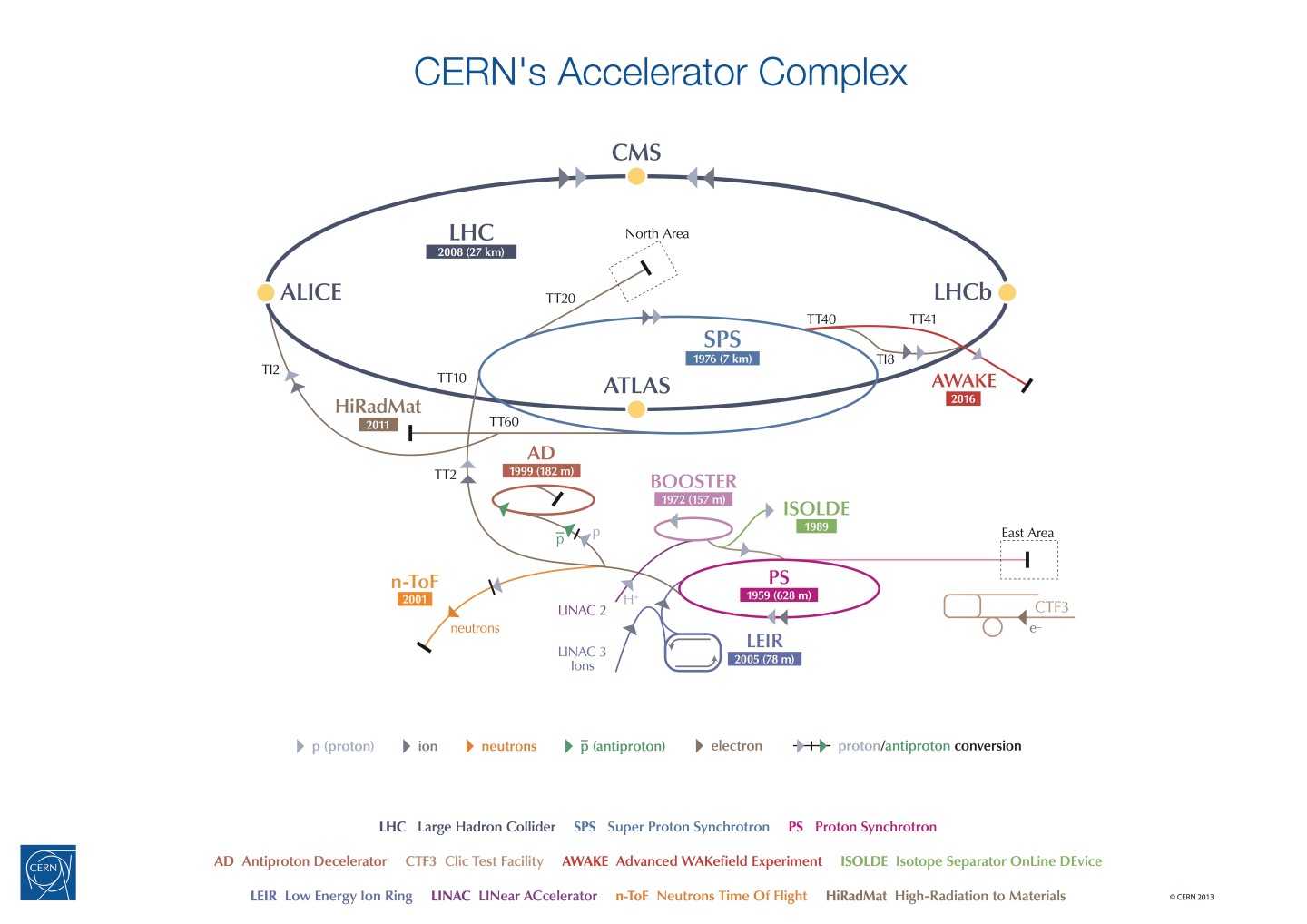 LHC 실험장치는 양성자빔을 생성하고 가속하는 LINAC2, LINAC3, PS, SPS, LHC Main Ring의 가속기와, 양성자빔 충돌 현상을 관찰, 기록하기 위한 ALICE, ATLAS, CMS, LHCb 등의 검출기로 구성되어 있다[4].
LHC 실험장치는 양성자빔을 생성하고 가속하는 LINAC2, LINAC3, PS, SPS, LHC Main Ring의 가속기와, 양성자빔 충돌 현상을 관찰, 기록하기 위한 ALICE, ATLAS, CMS, LHCb 등의 검출기로 구성되어 있다[4].
입자물리학자들이 LHC 실험을 통해 확인하고 답을 얻고자 하는 질문들은 다음과 같다[3-4].
1. 약전자기 대칭(electroweak symmetry)은 어떻게 깨지는가? 표준 모형(The Standard Model)에서 예측하는 힉스(Higgs) 메커니즘에 의한 것인가? 그렇다면, 힉스 보존(boson)의 질량은 무엇인가?
2. 표준 모형(The Standard Model)이 중입자(Baryon) 질량의 비를 정밀히 예측하는가? 아니라면, 표준 모형을 어떻게 확장해야 하는가?
3. 초대칭(Supersymmetry)이 존재하는가? 초대칭이 예측하는 추가 입자 (초짝입자)가 존재하는가?
4. 왜 물질과 반물질 사이에 명백한 비대칭이 있는가? (CP 위반(CP Violation))
5. 끈 이론(String theory) 등에 의해 예측된 추가 차원(Extra dimension)이 실재하는가?
6. 암흑 물질(Dark matter)은 무엇으로 이뤄진 것인가? 암흑 에너지의 정체는 무엇인가?
7. 왜 중력이 다른 상호작용에 비해 터무니없이 약한가? (계층 문제(Hierarchy problem))
입자 물리학자들이 우주의 근본을 이루는 입자들이 따르는 법칙을 발견하기 위해 여러 가지 가설과 모델을 만들어 예측했던 위와 같은 질문들에 대한 답을 찾고자 만든 실험장치가 바로 LHC이다. 위의 질문들 모두 중요하지만, LHC 실험의 가장 중요한 목적은 질량을 매개하는 입자로 표준모형(The Standard Model)에서 예측된 힉스 보존의 존재를 확인하는 것이었다. (결국 LHC의 ATLAS와 CMS 검출기에서 2012년 힉스 보존이 만든 것으로 보이는 이벤트가 검출되었다. 2012년의 힉스 보존 발견으로 힉스 보존의 존재를 이론으로 예측했던 에든버러 대학의 피터 힉스 교수와 브뤼셀자유대의 프랑스와 앙글레르 교수는 2013년 노벨 물리학상을 받았다.)
CERN의 국제 공동 연구진은 힉스 입자를 발견하기 위해 양성자빔을 충돌시키는 가속기를 건설했고, 이 가속기에서 일어나는 양성자 충돌 이벤트 데이터를 수집하기 위해 필요한 조건을 공학적으로 추정했다. 1990년대 초반 수행된 LHC 가속기 및 검출기 개념 설계 연구에서 LHC 가속기에서 양성자빔 충돌 이벤트는 25나노초마다 한번, 즉 약 40MHz(초당 4,000만 번)의 빈도로 일어난다. 이벤트 데이터를 수집, 기록하기 위한 검출 장치는 한 번의 충돌에서 약 1MB의 원시 데이터(raw data)가 수집되도록 디자인되었다.
LHC의 ATLAS, CMS 등의 검출기 디자인 파라미터를 통해 계산해보면 초당 약 10억 번의 양성자-양성자 충돌이 일어나기 때문에, 초당 발생하는 데이터는 약 1PB가 된다[5]. 이렇게 LHC에서 일어나는 현상을 분석하는 데 필요한 분석 시스템의 요구 사항을 정의하다 보니 당시로써는 상상할 수도 없을 만큼의 큰 데이터를 다뤄야 한다는 사실을 알게 되었다. 이것이 LHC 빅데이터 연구의 시작이었다.
LHC 건설 당시나 현재나 초당 1PB의 데이터를 모두 저장할 수 있는 데이터 저장 장치가 없을 뿐만 아니라, LHC를 건설할 당시의 전자공학 기술들로도 초당 1PB의 대용량 데이터를 처리, 가공할 수 없었다. 이런 기술적인 한계 때문에 현재 LHC 검출기의 데이터 처리 시스템에서는 원시 데이터의 약 1천분의 1인 초당 약 200개의 이벤트 데이터만 저장할 수 있었다. 일종의 필터링 시스템인 Level 1 트리거(trigger) 시스템에서 원시 데이터의 천분의 일만 버퍼에 저장해 처리하기 때문에 초당 약 200MB에서 1TB의 데이터가 생성되게 된다[5].
LHC는 하루에 10시간 동안 실험을 두 번 수행하게 되고, 1년에 300일 동안 양성자빔을 LHC 주 가속기(main ring)에 가둬 놓고 실험하게 된다. 위에서 얘기한 초당 200MB~1TB 데이터양에 LHC 운영 시간을 곱하고, LHC에서 운영되는 주 검출장치가 ATLAS, CMS, ALICE, LHCb 4대인 점을 고려하면 연간 LHC의 검출기들이 생산하는 데이터양이 약 15PB로 추산할 수 있다[5].
이렇게 추산한 데이터양을 바탕으로 2009년까지 LHC 빅데이터 처리를 위한 LHC 컴퓨팅 그리드를 연구개발, 구축하는 데 든 비용은 2009년 당시 CERN에서만 총 1억 6,800만 스위스 프랑, 우리나라 돈으로 약 1,700억 원에 달한다[6]. 이 비용은 CERN에서만의 비용이기 때문에, LHC 컴퓨팅 그리드에 참여한 국가별 티어-1, 티어-2 데이터센터의 LHC 컴퓨팅 그리드 구축 비용을 합치면 1조 원 이상이 투자됐을 것으로 보인다. LHC는 비용으로도 큰 프로젝트이지만, 데이터 처리를 위한 LHC 컴퓨팅 그리드 개발, 구축 및 통합만도 20여 년의 긴 시간이 소요된 큰 프로젝트였다.
위의 데이터 생산량 추정치를 넘어서는 데이터가 이미 LHC 검출기들에서 생산되고 있다. Run 1 기간이었던 2011년도에 이미 23PB, 2012년도에 이미 27PB의 데이터가 수집되었으며, Run 2 기간인 2015년에는 40PB의 원시데이터를 생산했다고 알려졌다. 곧 LHC가 Super-LHC로 성능이 업그레이드된 후 운영될 Run 3 기간(2020년~2022년)에는 연간 150PB, Run 4 기간(2023년~2029년)에는 연간 600PB의 데이터가 생산될 것으로 추정된다. 2028년까지 누적 데이터는 벌써 3.8Exabyte (3743PB)에 이를 것으로 추정되고 있다[7].
기술이 먼저인가, 비즈니스 모델이 먼저인가? – 빅데이터 비즈니스의 딜레마
빅데이터 비즈니스에서 항상 의견이 갈리는 부분 중의 하나가 비즈니스 모델이 먼저인가, 아니면 빅데이터 기술이 먼저인가 하는 부분이다. 마치 닭이 먼저냐, 달걀이 먼저냐 하는 문제 같아서 쉽게 결론을 내리기는 어렵지만, 필자는 비즈니스 모델이 먼저라는 얘기를 하고 싶다.
CERN의 과학자들이 LHC 실험을 시작한 것은 빅데이터 기술을 가지고 할 일을 찾기 위해 시작한 것이 아니었다. CERN에서 일하는 과학자들의 임무는 우주를 구성하는 근본 입자들이 따르는 물리적인 법칙과 근본 입자들을 탐색하고 찾아내는 것이었다. 그들의 임무를 온전하게 수행하기 위해서 높은 에너지의 양성자빔을 충돌시켜 실험할 필요가 있었던 것이다.
높은 에너지의 양성자빔을 충돌시킬 때 일어나는 입자 간 상호작용 현상을 기록하려다 보니, 입자의 궤적과 에너지 등의 정보를 기록할 수 있는 검출장치가 필요하게 되었다. 양성자빔들이 14TeV의 고에너지로 충돌해 생성된 입자들이 워낙 멀리까지 궤적을 그려서, 정확한 현상 분석을 위해 검출기의 크기가 커져 저장해야 하는 데이터의 양도 많아진 것이다.
양성자빔이 빛의 속도의 99.99999999%로 운동하기 때문에 2개의 양성자빔이 충돌하는 빈도도 초당 40만 번으로 매우 빠르게 일어나게 된다. 이렇게 빠르게 일어나는 양성자빔 충돌 때문에 초당 1PB의 데이터가 생성돼, LHC 컴퓨팅 그리드와 같은 막대한 양의 데이터를 처리, 분석할 수 있는 기술을 개발하게 된 것이다. LHC 실험을 수행하려던 과학자들에게 빅데이터는 그들 본연의 임무를 수행하기 위해 넘어서야 했던 기술적인 난제였던 것이지, 양성자빔 충돌을 빅데이터 기술을 써서 분석하면 모든 물리학적 문제가 풀리리라 생각했던 것은 아니었다.
지금까지 필자가 만나본 고객이나 빅데이터 기술을 어떻게 사업에 적용할지 문의하는 분들의 상당수가 뚜렷한 비즈니스 모델이나 빅데이터 기술을 왜 쓰려고 하는지에 대한 문제 분석 없이 막연하게 빅데이터 기술을 써서 데이터를 모으고 분석만 하면 조직의 많은 문제가 풀리리라 생각하는 분들이었다. 심지어는 데이터의 양이 많지도 않고, 기존에 이미 구축해놓은 데이터웨어하우스 시스템을 활용해도 충분한 문제에 대해서도 공연히 하둡 같은 빅데이터 인프라를 도입하기도 한다.
풀어야 할 비즈니스상의 문제, 빅데이터 시스템의 도입 목적을 분명하게 하지 않고 도입한 빅데이터 인프라들은 제대로 활용되기 어렵다. 막연하게 ‘데이터를 쌓아놓고 빅데이터 기술로 분석하면 유용한 정보가 나오겠지’라는 식의 접근도 빅데이터 시스템 도입의 효과를 보지 못하는 이유가 된다. 빅데이터 기술도 분명히 기술 나름의 한계가 있으며, 이러한 한계를 적절하게 평가하지 않고 새로운 기술이라고 해서 도입하는 것은 기업에 부담이 되고 투자 위험으로 돌아오게 된다.
빅데이터 자체가 비즈니스의 목적이나 비즈니스 모델이 될 수는 없다. 빅데이터를 다루는 것은 데이터 기반 비즈니스의 한 단면에 불과하다. 빅데이터를 수집하고 비즈니스에 맞는 정보로 가공하는 과정에서, 빅데이터를 비즈니스 운영 조건에 맞게끔 신속하고 빠르게 처리하는 시스템을 갖추는 과정에서 비즈니스의 경쟁력으로서 자리 잡게 된다. 빅데이터나 빅데이터 기술에 초점을 맞추기보다는, 지금 기업이나 조직이 당면한 문제, 해결해야 할 문제가 무엇인지 분명하게 정의하는 것이 중요하며 선행돼야 한다.
문제를 정의한 후 목표로 하는 비즈니스를 하려면 빅데이터 수집이 필요하다는 공감이 조직 내에 자리 잡아야 한다. 수집한 빅데이터를 처리ㆍ가공하여 가치 있는 정보로 바꾸는, 기업만의 차별화된 시스템을 갖추는 것이 경쟁사에 대한 튼튼한 진입장벽이라는 면밀한 검토와 확신이 필요하다. 이렇게 준비된 빅데이터 인프라가 비즈니스에 분명한 효과를 가져오리라는 판단이 들었을 때 빅데이터 시스템과 인프라를 도입하는 것이다. 빅데이터 시스템은 아무리 작은 규모로 도입하더라도 적지 않은 투자와 노력이 필요하고, 적절하게 활용되지 못하는 빅데이터 시스템은 이러한 투자와 노력을 의미 없는 것으로 만들기 때문에 빅데이터 시스템 도입은 신중해야 하는 것이다.
빅데이터를 기업의 금맥으로 만들어주는 것은 비즈니스 모델에 대한 철저한 고민과 분석, 빅데이터가 비즈니스 모델의 진입 장벽과 경쟁력으로서 효과가 있다는 확신으로부터 시작된다. 빅데이터 기술, 데이터 수집과 분석을 사업에서 부딪히는 문제에 대한 만병통치약으로 보는 실수를 하지 않도록 조심해야 할 것이다.
[참고문헌 및 그림 출처]
[1] Overall view of the LHC Accelerator - CERN Document Server,
http://cds.cern.ch/record/1708847
[2] The LHC Accelerator Complex - CERN Document Server,
http://cds.cern.ch/record/1621894
[3] 대형 강입자 가속기 – Wikipedia,
https://ko.wikipedia.org/wiki/대형_강입자_충돌기
[4] The Large Hadron Collider – Wikipedia,
https://en.wikipedia.org/wiki/Large_Hadron_Collider
[5] Taking a closer look at LHC - LHC DATA ANALYSIS,
http://lhc-closer.es/taking_a_closer_look_at_lhc/0.lhc_data_analysis
[6] Taking a closer look at LHC – LHC Cost,
http://lhc-closer.es/taking_a_closer_look_at_lhc/0.lhc_cost
[7] Dagmar Adamova (NPI AS CR Prague/Rez) and Maarten Litmaath (CERN), “Computing for the LHC: operations during Run 2 and getting ready for Run 3,” International Winter Workshop on Nuclear Physics 2016, Bormio, Italy,
https://indico.mitp.uni-mainz.de/event/56/session/1/contribution/30/material/poster/0.pdf
 *김진철 박사는 1997년 한국과학기술원에서 물리학 학사, 1999년 포항공과대학교에서 인공신경망에 대한 연구로 석사 학위를, 2005년 레이저-플라즈마 가속기에 대한 연구로 박사 학위를 받았다. 2005년부터 유럽입자물리학연구소(CERN)의 LHC 데이터 그리드 구축, 개발에 참여, LHC 빅데이터 인프라를 위한 미들웨어 및 데이터 분석 기술을 연구하였다. 이후 한국과학기술정보연구원(KISTI), 포항공과대학교, 삼성SDS를 거쳐 2013년부터 SK텔레콤에서 클라우드 컴퓨팅과 인공지능 기술을 연구하고 있다. 빅데이터와 인공지능 기술의 기업 활용 방안에 대해 최근 다수의 초청 강연 및 컨설팅을 수행하였다.
*김진철 박사는 1997년 한국과학기술원에서 물리학 학사, 1999년 포항공과대학교에서 인공신경망에 대한 연구로 석사 학위를, 2005년 레이저-플라즈마 가속기에 대한 연구로 박사 학위를 받았다. 2005년부터 유럽입자물리학연구소(CERN)의 LHC 데이터 그리드 구축, 개발에 참여, LHC 빅데이터 인프라를 위한 미들웨어 및 데이터 분석 기술을 연구하였다. 이후 한국과학기술정보연구원(KISTI), 포항공과대학교, 삼성SDS를 거쳐 2013년부터 SK텔레콤에서 클라우드 컴퓨팅과 인공지능 기술을 연구하고 있다. 빅데이터와 인공지능 기술의 기업 활용 방안에 대해 최근 다수의 초청 강연 및 컨설팅을 수행하였다. ciokr@idg.co.kr